
A Museum Without Walls: Technical Aspects
By: Anne Kling, Manager, Collections Databases
CMC's records on iDigBio
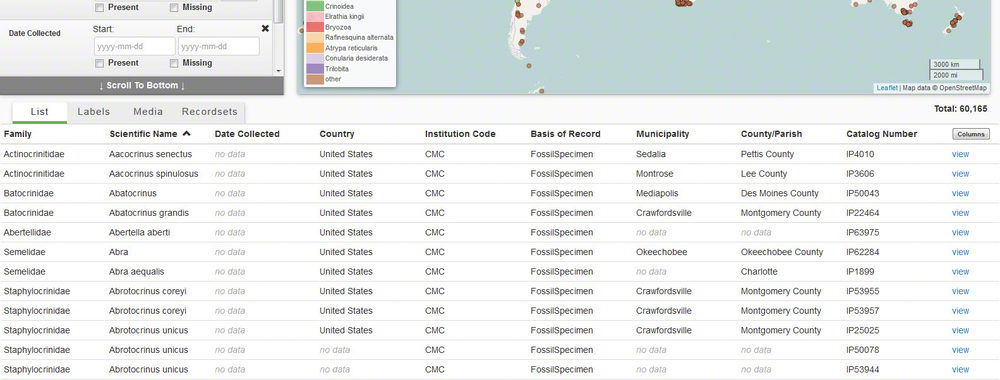
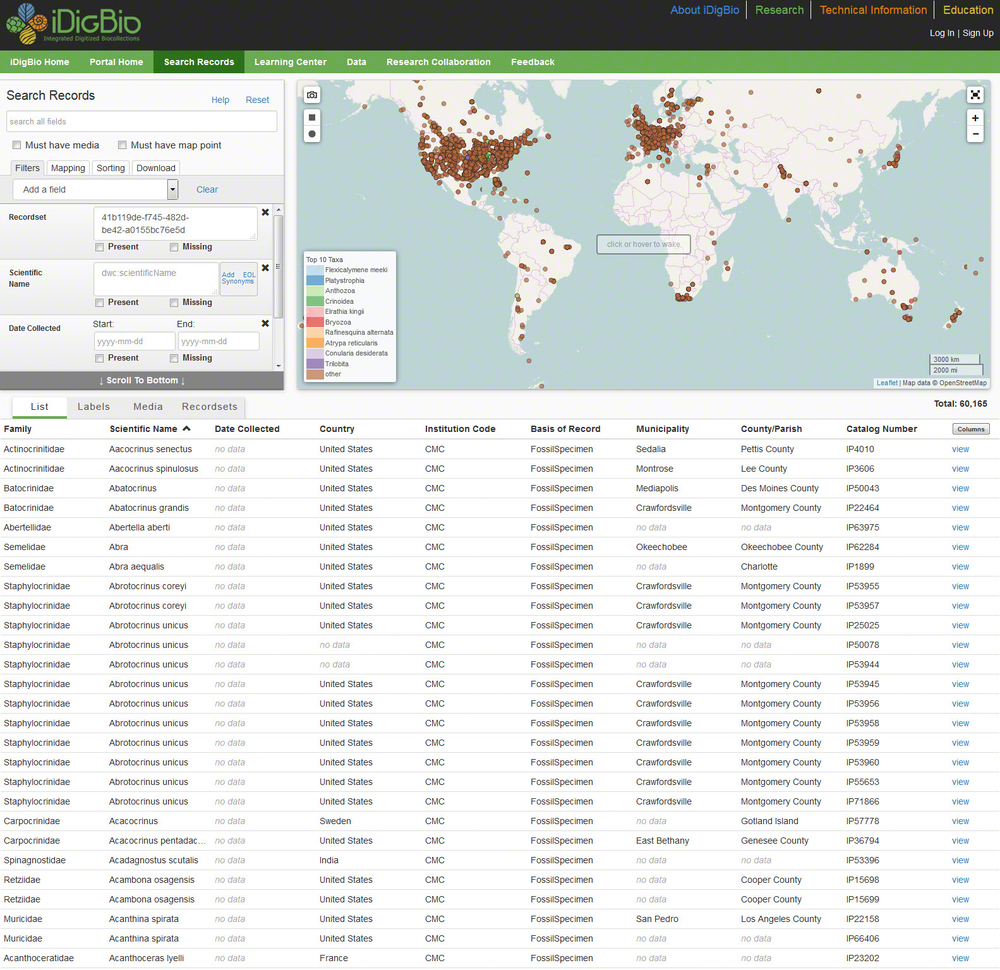
In an earlier post, we announced the sharing of over 60,000 of Museum Center's Invertebrate Paleontology records to the global iDigBio website and explained how this benefits the scientific community. But, how does this actually happen? What steps are involved to place our records on an international research platform?
First, our Curator of Invertebrate Paleontology, Dr. Brenda Hunda, and several volunteers and interns completed the cataloging and georeferencing of thousands of IP specimens. Georeferencing is the process of assigning geographic coordinates based on the collection locality. Once we were satisfied with the content and quality of the IP records in our EMu database system that we wanted to submit to iDigBio, we needed to map (or match) our fields to the fields used by iDigBio. Many organizations that deal with biological research, like iDigBio, use the Darwin Core as their preferred standard for sharing specimen information. The Darwin Core was created in 1998 and is an extension of the Dublin Core, a set of metadata elements for the exchange of library data, which were established three years earlier in Dublin, Ohio. Metadata means "data about data" and here we are referring to data about an item or specimen. The Darwin Core defines a set of fields for the exchange of biological data. We selected 51 fields from Darwin Core for this project, covering everything from basic specimen information (i.e., catalog number, number of items, date collected, name of person who collected the specimen) to taxonomic classification (kingdom, order, class, genus, species, etc.), stratigraphy (the rock strata or layers), and locality/georeferencing data (continent, country, state, city, latitude, longitude, etc.).
Next we took our list of fields, along with some additional specifications from the iDigBio data ingestion guide, to our database vendor. The vendor added the Darwin Core fields to our Emu system, and one field was selected as the trigger field. This would automatically cause our data to be copied into the new fields. It also allows the system to reformat and concatenate data (concatenate means to link together in the row or chain) in the new fields without modifying the data in our original fields.
The next step in the process was to load our records into the Integrated Publishing Toolkit (IPT) used by the GBIF network (Global Biodiversity Information Facility) The IPT is "a free open source software tool written in Java that is used to publish and share biodiversity datasets". We had the option of either installing and running the IPT ourselves and then sharing the records via an RSS feed or allowing our records to be hosted on the IPT at the Florida Museum of Natural History at the University of Florida. We chose the latter option. With the guidance of the staff at the University of Florida, we exported our IP records using the new Darwin Core fields, and they loaded them into their IPT. From there, the records were successfully ingested into iDigBio and were made available online with millions of biological and paleontological specimens from around the world.
